
Like Tweets in Rain: The Library of Congress Tries to Archive Twitter
Back in 2010, the US Library of Congress announced their intent to begin archiving Twitter–all of it. Dubbed the Twitter Research Access Project, every public tweet fired off since Twitter’s inception was to be stored for later retrieval in the hallowed library.
Unfortunately, it quickly became apparent that the LOC had bitten off more than it could chew.
By 2013, the Library had tackled the challenge of storing a set of 2006-2010 Twitter data and established mechanisms to reliably receive the real-time data streams, but had not yet begun making much of a dent into the larger issue: making the data useful. A single search of the 2006-2010 archive would take 24 hours to execute and return results, making it essentially unusable.
Around this time, e-mail conversations between academic researcher Michael Zimmer and the Library of Congress repeatedly cited “…technical issues…” and “…how to provide the material to researchers…” as outstanding concerns. In other words, the project itself seemed to be the technical hurdle.
After another two years passed, a Library spokesperson indicated that “…no date has been set for [the archive] to be opened.”
So…what gives? While my request for comment from the Library of Congress has yet to receive a response, there are a few likely hangups in this admirable yet audacious project:
Size
The LOC is receiving an unprecedented amount of data in this transaction with Twitter, at least when compared with their pre-agreement data responsibilities.
The Library received data in two chunks: one set of compressed tweets and metadata from 2006-2010, and a live feed via their firehose for real-time additions. By the end 2012, this data weighed in at a whopping 133 terabytes, or .78 terabytes per billion tweets. This is roughly 156 incremental terabytes per year, according to Internet Live Stats. In 2009, the LOC was only handling 74 terabytes of publicly available data, making the Twitter Archive Project an immediate 100% increase in data with significant double-digit growth for several years after, adding cost and complexity.
Retrieval
Unfortunately, size is just the tip of the iceberg for the LOC. After storage, the goal is to make the data publicly accessible to “bona fide researchers” for academic application of the data. An early indicator of how challenging this can be was the 24 hour period required for a single query to be performed in 2013. This suggests a serious issue with how the tweets are indexed, which is how the tweets are saved in a database (or several, depending on the query) to be quickly served up to users. The alternative would be reviewing the entire database for query hits for every query, which would be technically ludicrous.
At the very least, the LOC is likely employing a form of inverted indexing and citation indexing in order to store tweets based on the words within them and assess overall popularity (RTs and replies). The citation indexation likely poses an especially difficult interpretation challenge.
The number of RTs, replies, or likes is not always indicative with the importance of a tweet.
A close analog is how links are used to order search results. They have long been recognized as a critical ranking signal for organic search and the cornerstone of PageRank, a key algorithm to Google’s early success. However, on Twitter, the number of RTs, replies, or likes is not always indicative with the importance of a tweet. Consider the popularity of big brands and celebrities.
For instance, Twitter received a great deal of praise for its role in the Arab Spring protests, allowing activists and civilians to coordinate, and the public to “listen in” from around the world. These tweets have historical significance that may be difficult to tease out from the data due to lack of citations (e.g.. RTs) or other associated metadata. Querying by time and location would help surface this content, but until the LOC reveals how users will be able to query their database, it remains to be seen how many tools a user will have when navigating the deep mixed bag of Twitter content. It is hard to imagine the LOC creating a user experience that is not tedious and a search results page that is not riddled with low quality tweets.
Here is an example of searching Twitter for the “top” #arabspring tweets from 2011:
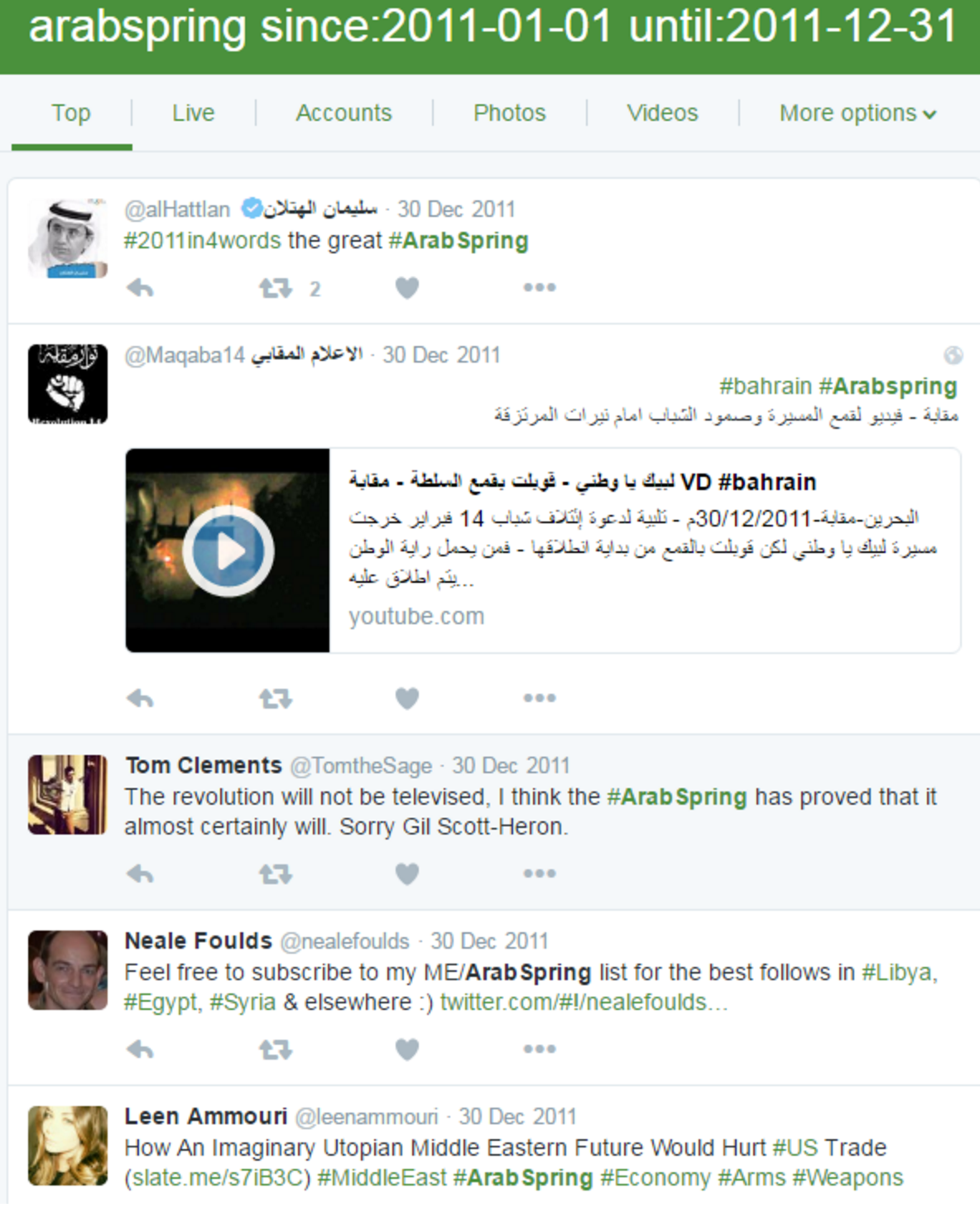
Even Twitter has issues determining relevancy of its own content.
Not Even Google is Trying to Do This at Scale
Google began experimenting with displaying Twitter results in 2010, but eventually put the project on hold due to scaling issues. Yes, Google struggled with this same project.
“It was an enormous amount of data to index. Working at such a scale in real time quickly became very difficult,” shared one former Googler employed while the project was active.
Google struggled with this same project.
Fast forward five years and Google was ready to take another stab at it. In May 2015, they once again were showing tweets in real time within its search result pages. With complete firehose access, just like the LOC, Google was faced with the same challenges of indexing tweets and figuring out how to serve the best results for the user. While the use case of a Google user is certainly different than a LOC-sanctioned academic, their goals are aligned: quickly return relevant results.
By June 2015, Google was only indexing 12% of one study’s sample set, biased heavily towards the number of followers of the tweet’s author, choosing to not to store 88% of the tweets it had access to. Whether this was an issue of technical feasibility or sussing out which tweets are worth serving to users has not been disclosed. In this context, attempting to store and organize 100% of Twitter seems like a dreadful task, especially for a group that doesn’t specialize in data of this size.
Godspeed, LOC engineers
Considering the size of the project, the complexity of the analysis, and the debatable value of 100% Twitter indexation, I can’t help but look at this project with a mixture of amusement (because who doesn’t enjoy a good government folly?) and dread (both for the engineers and taxpayers). With six years gone and little to show for it, I would not be surprised for this project to launch in a significantly abridged version, or disappear completely. While some parts of the web are becoming stickier, the notion of complete social media archiving simply appears to be out of reach with today’s technology.
Kyle Risley is an SEO expert at Vistaprint and also provides freelance SEO consulting. When he is away from his keyboard, he’s usually at a concert or digging through records.

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.